基础
术语
- 字符集(character set): 一个系统支持的所有抽象字符的集合
- 字符映射(character map)
- 字符编码(character encoding): 一套法则, 使用该法则能够对字符的一个集合进行配对
- 代码页(code page)
这些虽然有些不同, 但是在历史上往往表述时又是同义概念
进制
- 2(Binary)
- 8(Oct)
- 10(Decimal)
- 16(Hex)
- 0x prefix in javascript
- 比如: 0x00: 00000000, 0x7F: 01111111
容量单位
- 1bit(位, 小b) 为 0/1 的单位
- 1Byte(字节, 大B) = 8bit
- 1K = 1024
- 1M = 1024K
- 1G = 1024M
- 1T = 1024G
- 1P = 1024T
ASCII
American Standard Code for Information Interchange, 美国信息交换标准代码
8bit(所以一个字节是8 bit), 最多可有 256 个字符
第一位为 0 的(0-127)属于基本字符表, 比如 A 是 65(0x41) a 则是 97(0x61), 最早的英语环境下使用这个就可以了
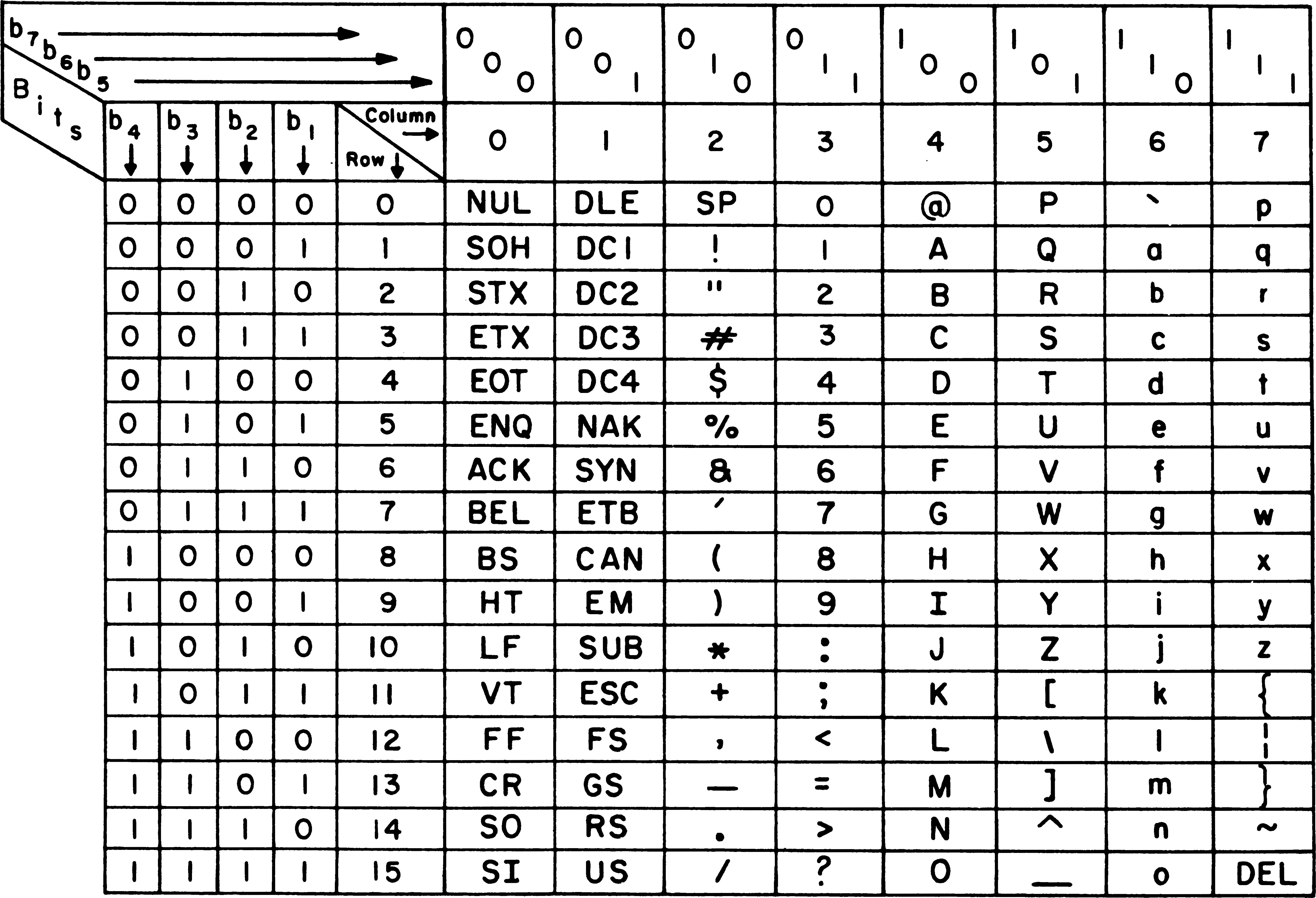
万码奔腾的年代
Extended ASCII
第一位为 1 的(128-255)属于扩展字符表(Extended ASCII), 扩充出来的符号包括表格符号、计算符号、希腊字母和特殊的拉丁符号, 他的取值在不同的编码系统中都有所不同 一些主要的 Extended ASCII 的 编码系统有:
- Dos
- Code page 437: 始祖IBM PC(个人计算机)或MS-DOS使用的字符编码
- ISO/IEC 8859
- ISO 8859-1 (Latin-1) - 西欧语言
- ISO 8859-2 (Latin-2) - 中欧语言
- ISO 8859-3 (Latin-3) - 南欧语言
- ISO 8859-4 (Latin-4) - 北欧语言
- ISO 8859-5 (Cyrillic) - 斯拉夫语言
- etc…
- ISO 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
- Windows code page 又被称作 ANSI code page
- Windows-1250 (Latin-2) - 中欧语言
- Windows-1251 (Cyrillic) - 斯拉夫语言
- Windows-1252 (Latin-1) - 西欧语言
- etc…
- Windows-1258 - 越南语
- 其他
亚洲文字
- GB2312(GB0)
- 两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(高字节)从 0xA1 用到 0xF7,后面一个字节(低字节)从0xA1到0xFE
- 也就是说一个汉字需要用 16 bit 来表示
- 这些字节总共可以表示 87 * 94 = 8178 个字符, 包括了大多数汉子和全角字符
- 共收录了 6763 个汉字
- 早期的区位码输入就是通过这种方式输入汉字的
- 不能处理总理的名字…陶喆也很尴尬…
- GBK(k: 扩展)
- Windows 定义出来的东西, 不是标准但是成为了事实标准
- Windows 系统里仍然有多 APP 延续了 GBK 标准
- 查看 windows code page:
chcp- 一般都是 936 → GBK
- GB18030: 基于 GBK 接续扩展了一些民族语言等字符
- 两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(高字节)从 0xA1 用到 0xF7,后面一个字节(低字节)从0xA1到0xFE
- BIG5
- 用于繁体中文
- 还记得小时候游戏有乱码的时候, 要用南极星转 BIG5
 塞班时代, 非中文世界的手机里还有默认中文字符无法显示的问题
塞班时代, 非中文世界的手机里还有默认中文字符无法显示的问题
Unicode
将这个世界上所有的符号纳入其中, 每一个符号都给予一个独一无二的编码, 理论上可以容纳 100 多万个符号, 仍然在不断增加中(考古, 新词, emoji)
例如 U+0041 表示为 A U+535A 表示为 博
Mac 自带的程序猿计算器上就可以方便的查询 Unicode
- Unicode 字符平面映射
- 告诉了我们某一类的字符在 Unicode 里的位置
- 主要使用的是 BMP(只有最低4位有值:U+XXXX): 基本多文种平面
- 汉字主要分布在中日韩统一表意文字(CJK Unified Ideographs)
- 令和(U+32FF)加入 Unicode, 却不在中日韩兼容字符里… 位置不够了..
- 汉字主要分布在中日韩统一表意文字(CJK Unified Ideographs)
存储 Unicode 的方法
- UTF-8
- 变长编码方式(1-4字节)
- 如果为了存储汉字而一股脑的把英文字符的存储也定为 16bit 是一种极大的浪费, 甚至有一些更大的符号需要更多的 bit 表示
- 对于单字节(8bit)的符号: 字节的第一位设为0, 后面7位为这个符号的 Unicode 码. 因此对于英语字母, UTF-8 编码和 ASCII 码是相同的
- 对于 n 字节的符号(n > 1): 第一个字节的前 n 位都设为1, 第n + 1位设为0, 后面字节的前两位一律设为10. 剩下的没有提及的二进制位, 全部为这个符号的 Unicode 码.
- 也就是说, 如果一个字节的第一位是0, 则这个字节单独就是一个字符. 如果第一位是1, 则连续有多少个1, 就表示当前字符占用多少个字节
- 000000 - 00007F: 0xxxxxxx
- 000080 - 0007FF: 110xxxxx 10xxxxxx
- 000800 - 00FFFF: 1110xxxx 10xxxxxx 10xxxxxx
- 010000 - 10FFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- etc…
- 所以开始的128个字符(ASCII)只需1字节, 接下来的一些西方的字符和符号需要两个字符. 中文等亚洲文字需要3个字节, 剩余字符需要四个字节
A⇒U+0041⇒01000001博:U+535A⇒11100101 10001101 10011010
- 其他
- UTF-16(UCS-2 + Surrogate pair, 这样就可以表示比 65536 更多个字符了)
- 用2个或4个字节表示
- 需要表明字节序
- UTF-32(UCS-4)
- 用4个字节表示
- 需要表明字节序
- UTF-16(UCS-2 + Surrogate pair, 这样就可以表示比 65536 更多个字符了)
- BOM: byte order mark
- 出现在文件开头
- 字节序
- Big Endian 是指低地址端存放高位字节; Little Endian 是指低地址端存放低位字节.
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-endian)敲开还是从小头(Little-endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位
- 以汉字博为例, Unicode 码是535A, 需要用两个字节存储. 存储的时候,53在前,5A在后是 Big endian 方式; 5A在前, 53在后是 Little endian 方式
- 如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式; 如果头两个字节是FF FE, 就表示该文件采用小头方式
- UTF-8: EF BB BF
- UTF-16 little-endian: FF FE
- UTF-16 big-endian: FE FF
- UTF-32 little-endian: FF FE 00 00
- UTF-32 big-endian: 00 00 FE FF
emoji 组合字符
- 通过零宽度连接符
U+200D实现 - 比如
U+1F468 U+200D U+1F469 U+200D U+1F467就会显示为一个 Emoji 👨👩👧[..."👨👩👧👦"]
手持两把锟斤拷 口中疾呼烫烫烫 脚踏千朵屯屯屯 笑看万物锘锘锘
- 锟斤拷
- GBK 转到 Unicode 时, 会将没法展示的 Unicode 符号, 替换为 U+FFFD
�(replacement character), UTF-8 编码为:1110,1111 1011,1111 1011,1101→ 0xEFBFBD - 如果有连续两个无法展示的符号, 则存储为 0xEF 0xBF 0xBD 0xEF 0xBF 0xBD
- GBK→ 锟(0xEFBF)斤(0xBDEF)拷(0xBFBD)
- GBK 转到 Unicode 时, 会将没法展示的 Unicode 符号, 替换为 U+FFFD
- VC 中文版中的
烫烫烫和屯屯屯 - 锘锘锘: UTF-8 BOM 头 (0xEFBB)
Javascript 转换 API
- UTF-16
- String.prototype.charCodeAt(): returns an integer between 0 and 65535 representing the UTF-16 code unit at the given index(并不适用于增补字符)
- String.fromCharCode()
- Unicode code point
- String.prototype.codePointAt()
- String.fromCodePoint()
- encodeURIComponent 是基于 UTF-8 的
Base64
Base64是一种基于64个可打印字符(A-Z, a-z, 0-9, +, /)来表示二进制数据的表示方法。每6个比特为一个单元, 对应某个可打印字符 若原数据长度不是3的倍数时且剩下1个输入数据,则在编码结果后加2个=;若剩下2个输入数据,则在编码结果后加1个=
- 用于URL的改进Base64编码: 它不在末尾填充
=, 并将标准Base64中的+和/分别改成了-和_
坑 不要忽略 zero width space 的存在…
字符编码那点事:快速理解ASCII、Unicode、GBK和UTF-8(这里对 GB 编码的表述感觉有失公允) Kerning Panic · 字谈字串(二) Unicode 字符百科